Gender Inequality in Film
Nhi Hin
2021-03-16
Last updated: 2021-12-06
Checks: 7 0
Knit directory: TidyTuesday/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20210215) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version fc5d76f. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rproj.user/
Untracked files:
Untracked: output/edges2.csv
Untracked: output/nodes2.csv
Unstaged changes:
Modified: analysis/_site.yml
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/gender.Rmd) and HTML (docs/gender.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| html | a751071 | Nhi Hin | 2021-03-23 | Build site. |
| Rmd | 66ebe88 | Nhi Hin | 2021-03-23 | wflow_publish(“analysis/gender.Rmd”) |
| html | 2144705 | Nhi Hin | 2021-03-16 | Build site. |
| html | b0b17f3 | Nhi Hin | 2021-03-16 | Build site. |
| html | 4d5c860 | Nhi Hin | 2021-03-16 | Build site. |
| Rmd | d1f85dc | Nhi Hin | 2021-03-16 | add gender film analysis |
Import Data
- Import in data as follows:
tuesdata <- tidytuesdayR::tt_load(2021, week = 11)--- Compiling #TidyTuesday Information for 2021-03-09 ------- There are 2 files available ------ Starting Download ---
Downloading file 1 of 2: `raw_bechdel.csv`
Downloading file 2 of 2: `movies.csv`--- Download complete ---movies <- tuesdata$movies
raw_bechdel <- tuesdata$raw_bechdel- Preview data:
raw_bechdel# A tibble: 8,839 x 5
year id imdb_id title rating
<dbl> <dbl> <chr> <chr> <dbl>
1 1888 8040 0392728 Roundhay Garden Scene 0
2 1892 5433 0000003 Pauvre Pierrot 0
3 1895 6200 0132134 The Execution of Mary, Queen of Scots 0
4 1895 5444 0000014 Tables Turned on the Gardener 0
5 1896 5406 0000131 Une nuit terrible 0
6 1896 5445 0223341 La fee aux choux 0
7 1896 6199 0000012 The Arrival of a Train 0
8 1896 4982 0000091 The House of the Devil 0
9 1897 9328 0000041 Bataille de neige 0
10 1898 4978 0135696 Four Heads Are Better Than One 0
# … with 8,829 more rowsmovies# A tibble: 1,794 x 34
year imdb title test clean_test binary budget domgross intgross code
<dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <chr> <chr> <chr>
1 2013 tt171… 21 &… notalk notalk FAIL 1.3 e7 25682380 42195766 2013…
2 2012 tt134… Dredd 3D ok-di… ok PASS 4.5 e7 13414714 40868994 2012…
3 2013 tt202… 12 Year… notal… notalk FAIL 2 e7 53107035 1586070… 2013…
4 2013 tt127… 2 Guns notalk notalk FAIL 6.1 e7 75612460 1324930… 2013…
5 2013 tt045… 42 men men FAIL 4 e7 95020213 95020213 2013…
6 2013 tt133… 47 Ronin men men FAIL 2.25e8 38362475 1458038… 2013…
7 2013 tt160… A Good … notalk notalk FAIL 9.2 e7 67349198 3042491… 2013…
8 2013 tt219… About T… ok-di… ok PASS 1.2 e7 15323921 87324746 2013…
9 2013 tt181… Admissi… ok ok PASS 1.3 e7 18007317 18007317 2013…
10 2013 tt181… After E… notalk notalk FAIL 1.3 e8 60522097 2443731… 2013…
# … with 1,784 more rows, and 24 more variables: budget_2013 <dbl>,
# domgross_2013 <chr>, intgross_2013 <chr>, period_code <dbl>,
# decade_code <dbl>, imdb_id <chr>, plot <chr>, rated <chr>, response <lgl>,
# language <chr>, country <chr>, writer <chr>, metascore <dbl>,
# imdb_rating <dbl>, director <chr>, released <chr>, actors <chr>,
# genre <chr>, awards <chr>, runtime <chr>, type <chr>, poster <chr>,
# imdb_votes <dbl>, error <lgl>Analysis Part 1 - The Bechdel Test Over Time
- Let’s try to reproduce the following plot from the FiveThirtyEight article.

- The scoring seems to be coming from the
test(orclean_test) in themoviesdata.
movies$clean_test %>% unique()[1] "notalk" "ok" "men" "nowomen" "dubious"- The histogram below shows that each year, there are more movies.
movies %>%
ggplot(aes(x = year, fill = clean_test)) +
geom_bar() +
ggtitle("The Bechdel Test Over Time")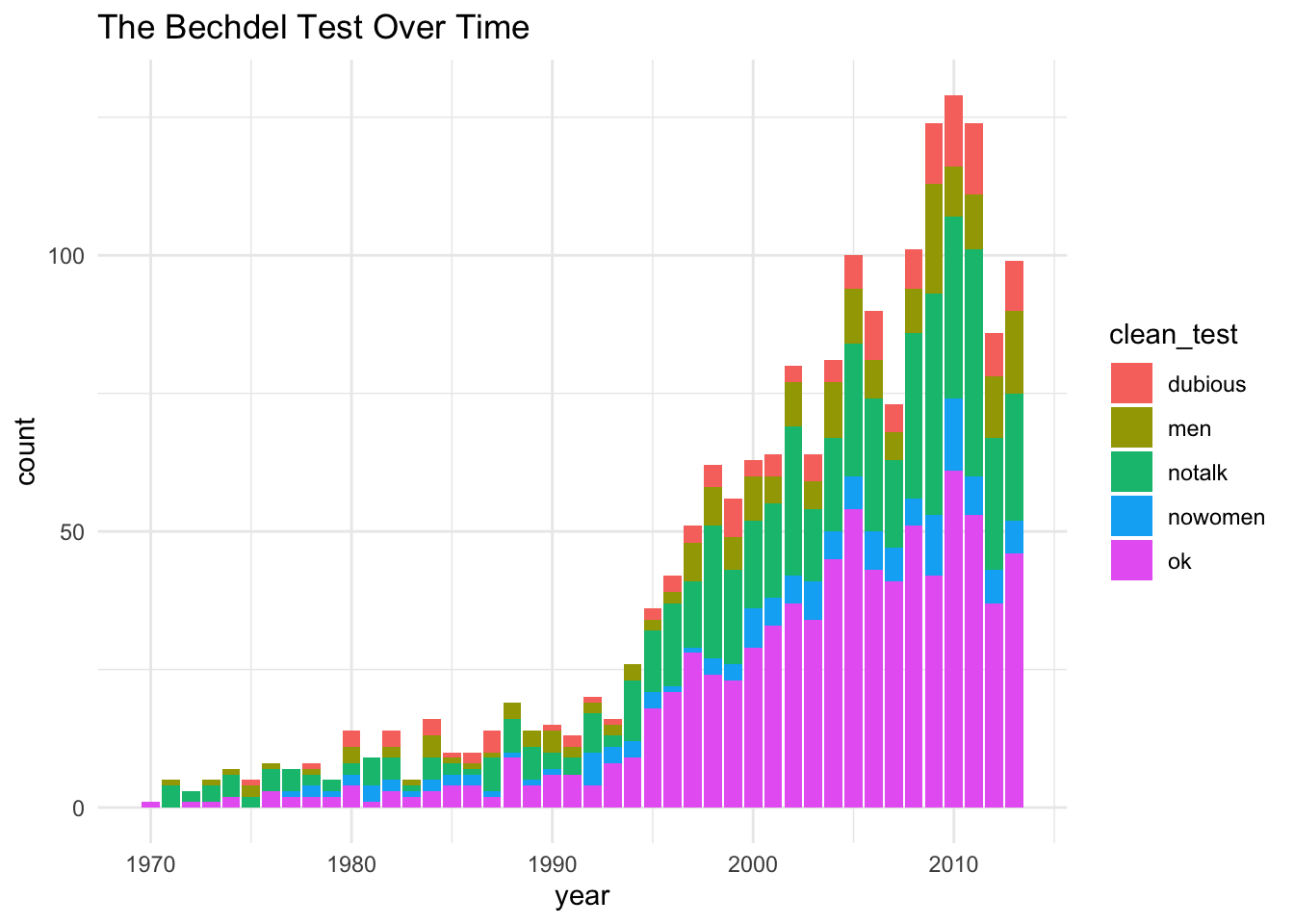
| Version | Author | Date |
|---|---|---|
| 4d5c860 | Nhi Hin | 2021-03-16 |
- In the FiveThirtyEight plot, they bin the years, and show the values as percentages rather than exact values. Let’s try to do this. First, we set the
breaksaccordingly.
# Adapted from https://www.jdatalab.com/data_science_and_data_mining/2017/01/30/data-binning-plot.html
# set up cut-off values
breaks <- c(1970, 1975, 1980, 1985, 1990, 1995, 2000, 2005, 2010, 2013)
# specify interval/bin labels
tags <- c("[1970-1974)",
"[1975-1979)",
"[1980-1984)",
"[1985-1989)",
"[1990-1994)",
"[1995-1999)",
"[2000-2004)",
"[2005-2009)",
"[2010-2013)")
# bucketing values into bins
group_tags <- cut(movies$year,
breaks=breaks,
include.lowest=TRUE,
right=FALSE,
labels=tags)
# inspect bins
summary(group_tags)[1970-1974) [1975-1979) [1980-1984) [1985-1989) [1990-1994) [1995-1999)
21 33 58 67 90 247
[2000-2004) [2005-2009) [2010-2013)
352 488 438 # order factor
movies$year_bin <- factor(group_tags,
levels = tags,
ordered = TRUE)- I’m also going to reorder the
clean_testso that it matches the FiveThirtyEight plot.
movies$clean_test %<>% factor(levels = c("ok", "dubious", "men", "notalk", "nowomen"))- Redo the bar plot for the bins, and change position to fill in order to make it show percentages (see https://www.r-graph-gallery.com/48-grouped-barplot-with-ggplot2.html).
movies %>%
ggplot(aes(x=year_bin, fill = forcats::fct_rev(clean_test))) +
geom_bar(position = "fill", color = "white")+
scale_x_discrete(labels = c("[1970-1974)" = "1970-74",
"[1975-1979)" = "",
"[1980-1984)" = "1980-84",
"[1985-1989)" = "",
"[1990-1994)" = "1990-94",
"[1995-1999)" = "",
"[2000-2004)" = "2000-04",
"[2005-2009)" = "",
"[2010-2013)" = "2010-13")) +
labs(x = "Year", y = "Percentage (%)", fill = "") +
scale_y_continuous(breaks = c(0, 0.25, 0.5, 0.75, 1),
labels = c("0", "25", "50", "75", "100")) +
ggtitle("The Bechdel Test Over Time",
subtitle = "How women are represented in movies") +
scale_fill_manual(values = c("#ff2600", "#ff937f", "#ffcac0", "#6ab2d5", "#008fd5"),
labels = c("ok"="Passes Bechdel Test",
"dubious"="Dubious",
"men"="Women only talk about men",
"notalk"="Women don't talk to each other",
"nowomen"="Fewer than two women"))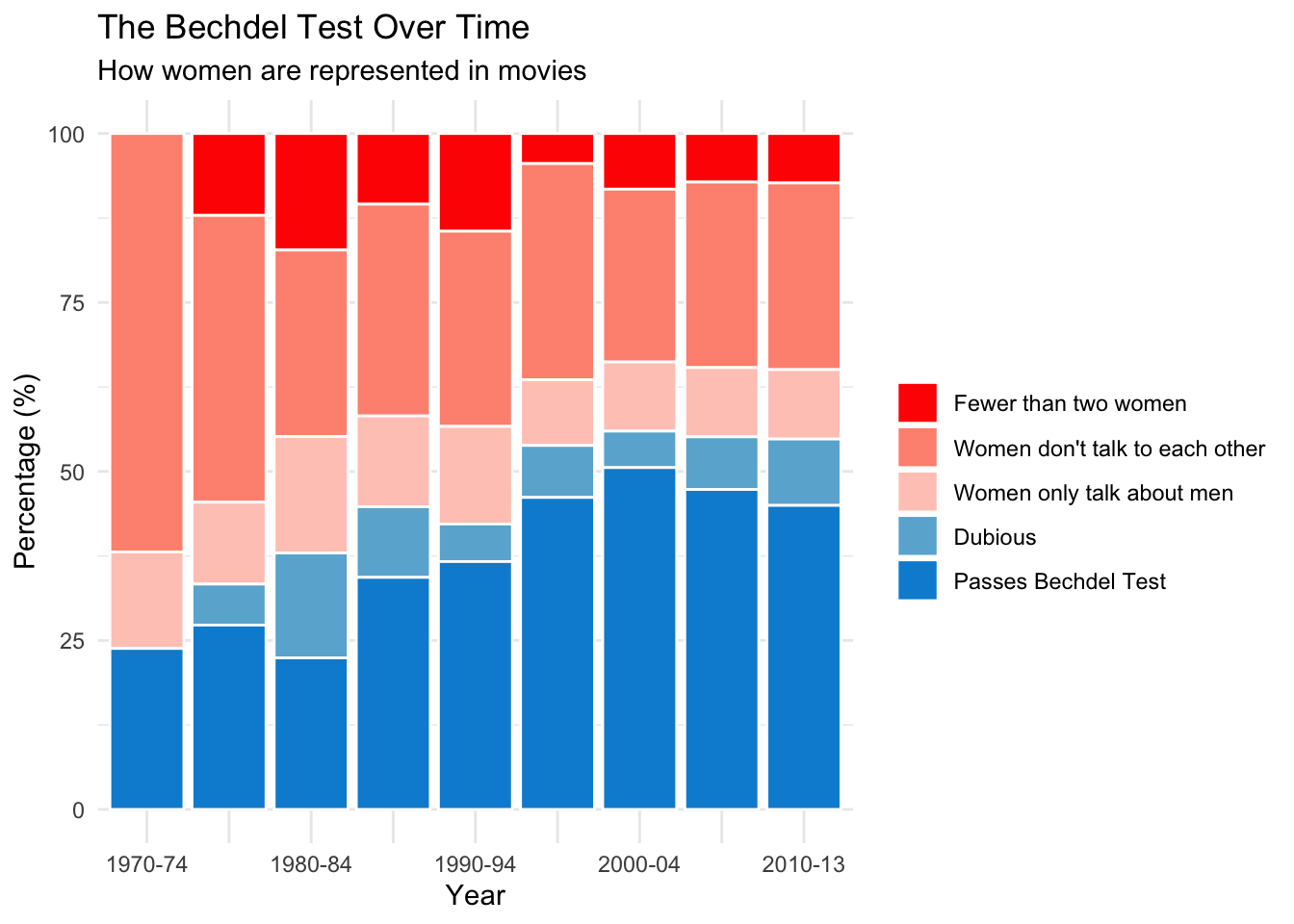
Analysis Part 2 - Median Budget for Films
- Also trying to recreate this plot:

The
budget_2013variable makes it simple as this contains dollars which have already been adjusted to be in 2013 dollars as the FiveThirtyEight plot shows.We will prepare a summarised data.frame that contains the median of
budget_2013across all films in each category of the Bechdel Test result stored inclean_test.
movies_summary <- movies %>%
dplyr::group_by(clean_test) %>%
dplyr::summarise(median_budget_2013 = median(budget_2013)) %>%
dplyr::mutate(label = case_when(
clean_test == "ok" ~ "Passes Bechdel Test",
clean_test == "dubious" ~ "Dubious",
clean_test == "men" ~ "Women only talk about men",
clean_test == "notalk" ~ "Women don't talk to each other",
clean_test == "nowomen" ~ "Fewer than two women"
)) %>%
dplyr::mutate(median_budget_2013_M = median_budget_2013 / 1e6)- The bar plot can now be plotted as follows:
movies_summary %>%
ggplot(aes(x = median_budget_2013_M, y = label)) +
geom_bar(stat = "identity", fill = "cornflowerblue") +
labs(x = "millions of dollars", y = "") +
ggtitle("Median Budget for Films Since 1990",
subtitle = "2013 dollars")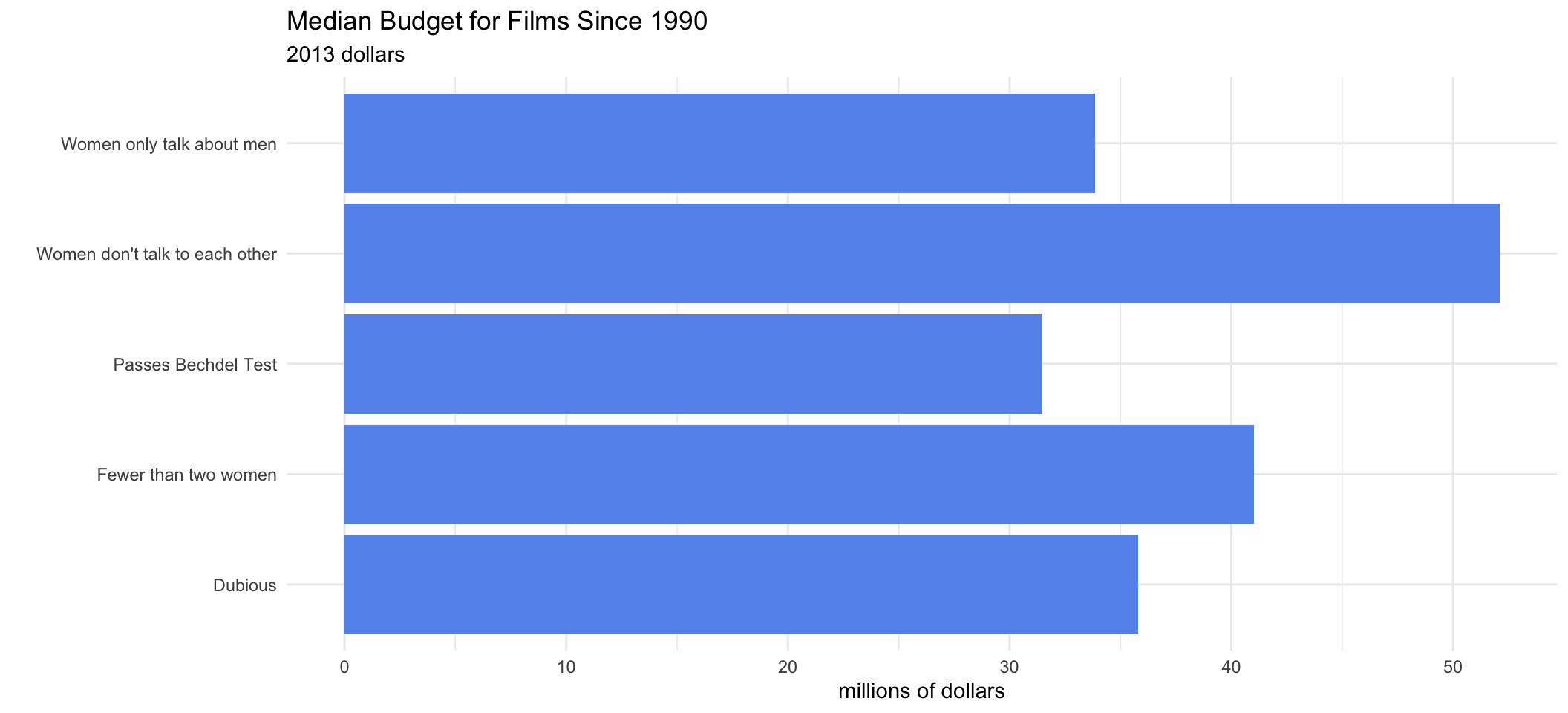
| Version | Author | Date |
|---|---|---|
| a751071 | Nhi Hin | 2021-03-23 |
Analysis Part 3 - Sankey Plot (Incomplete)
- This part of the analysis comes from Jodi, who showcased a very interesting and effective use of Sankey plots in the Slack channel.
nodes <- movies$clean_test %>%
unique() %>%
as.data.frame %>%
set_colnames("name") %>%
tibble::rowid_to_column("node")
sessionInfo()R version 4.0.3 (2020-10-10)
Platform: x86_64-apple-darwin17.0 (64-bit)
Running under: macOS Mojave 10.14.6
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.0/Resources/lib/libRblas.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.0/Resources/lib/libRlapack.dylib
locale:
[1] en_AU.UTF-8/en_AU.UTF-8/en_AU.UTF-8/C/en_AU.UTF-8/en_AU.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] htmlwidgets_1.5.2 networkD3_0.4 scales_1.1.1 ggplot2_3.3.3
[5] magrittr_2.0.1 dplyr_1.0.5 tidytuesdayR_1.0.1 workflowr_1.6.2
loaded via a namespace (and not attached):
[1] tidyselect_1.1.0 xfun_0.23 bslib_0.2.4 purrr_0.3.4
[5] colorspace_2.0-0 vctrs_0.3.7 generics_0.1.0 htmltools_0.5.1.1
[9] usethis_1.6.3 yaml_2.2.1 utf8_1.1.4 rlang_0.4.10
[13] jquerylib_0.1.3 later_1.1.0.1 pillar_1.6.0 withr_2.3.0
[17] glue_1.4.2 DBI_1.1.0 selectr_0.4-2 readxl_1.3.1
[21] lifecycle_1.0.0 stringr_1.4.0 munsell_0.5.0 gtable_0.3.0
[25] cellranger_1.1.0 rvest_1.0.0 evaluate_0.14 forcats_0.5.1
[29] labeling_0.4.2 knitr_1.30 httpuv_1.5.4 curl_4.3
[33] fansi_0.4.1 Rcpp_1.0.5 readr_1.4.0 promises_1.1.1
[37] jsonlite_1.7.2 farver_2.0.3 fs_1.5.0 hms_1.0.0
[41] digest_0.6.27 stringi_1.5.3 rprojroot_2.0.2 grid_4.0.3
[45] cli_3.0.1 tools_4.0.3 sass_0.3.1 tibble_3.1.1
[49] crayon_1.4.1 whisker_0.4 pkgconfig_2.0.3 ellipsis_0.3.1
[53] xml2_1.3.2 lubridate_1.7.10 assertthat_0.2.1 rmarkdown_2.8
[57] httr_1.4.2 rstudioapi_0.13 R6_2.5.0 igraph_1.2.6
[61] git2r_0.27.1 compiler_4.0.3